
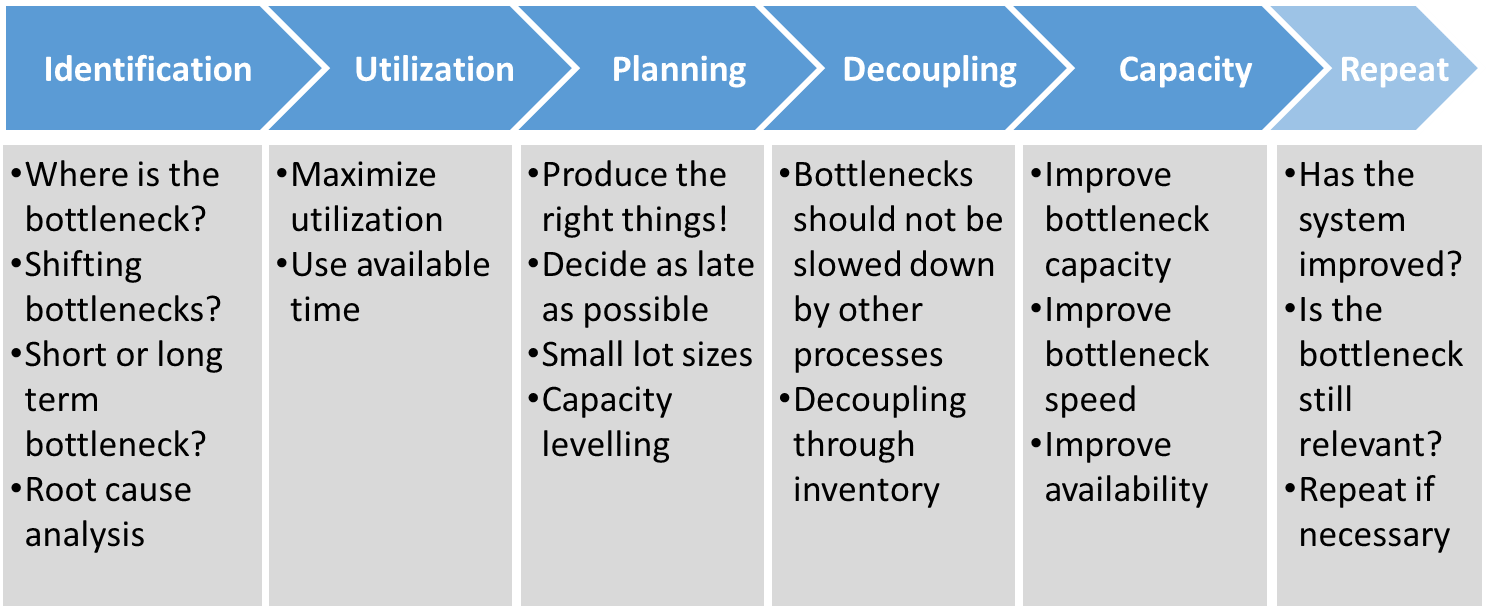
 Bottleneck detection and management are important in managing or increasing your production capacity. In the first post of this series I talked about fundamentals and improving utilization. The second post looked at the impact of planning on the overall production capacity. This final post in the series will look at the effect of decoupling and the actual process capacity improvement. Just as a quick recap, below is the overall structure for bottleneck management. In this post we will discuss the last two elements, decoupling and capacity, before closing this post series.
Bottleneck detection and management are important in managing or increasing your production capacity. In the first post of this series I talked about fundamentals and improving utilization. The second post looked at the impact of planning on the overall production capacity. This final post in the series will look at the effect of decoupling and the actual process capacity improvement. Just as a quick recap, below is the overall structure for bottleneck management. In this post we will discuss the last two elements, decoupling and capacity, before closing this post series.
Decoupling Your Bottleneck
By their nature, bottlenecks shift. The less bottlenecks shift, the less likely is it that the largest bottleneck is temporary slowed down by other secondary bottlenecks. The larger the buffers, the less likely it is that a bottleneck will shift. Hence you can improve your system capacity by adding buffers before and after the largest bottleneck process.
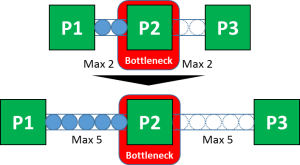
Of course, this is also a trade-off. Through decoupling, you slightly increase your inventory and your system response time becomes more sluggish. But here is a small trick: By their nature, buffers in front of the bottleneck are usually full. Hence you get all the negative effects that come with increased inventory, like tied-up materials and slower throughput time.
Buffers after the bottleneck, on the other hand, are usually empty. They are filling up when an actual decoupling toward downstream processes is needed. Hence you get all the benefits of decoupling, but few of the disadvantages of inventory (yes, you still need to have the space ready to store the parts). Therefore, buffer after the bottleneck may be preferable to buffer before the bottleneck.
However, in all likelihood, you should not drop your buffer before the bottleneck to zero, otherwise your bottleneck will lose efficiency due to occasional not-decoupled lack of parts coming from upstream.
Also, just because you are decoupling the bottleneck does not mean that there are no other buffers needed in the system. If you buffer only your bottleneck and nothing else, chances are that the interactions between the other processes overall starve and block the otherwise biggest bottleneck frequently. Hence it is good practice to have at least some buffer between stations.

This is, of course, unless the stations are locked in speed like a conveyor belt. For example, automotive assemblies often have no inventory between stations, but only between larger line segments. As for determining the buffer size, this is tricky business. The common industry approach is to take the expert estimate of someone knowledgeable on the shop floor (i.e., a rough guess of someone who knows at least a little about the system). There are mathematical methods available too (see Determining the Size of Your FiFo Lane – The FiFo Formula), but I still recommend the expert estimate approach. However, if you insist on a calculation, you can use my FiFo calculator.
Capacity Improvements
Update or Install New Machines
Finally, the last approach to improve your system performance is to improve the capacity of the bottleneck. Most often this involves updating existing or installing new machines (i.e., lots of time and money). For some strange reason, this slow and expensive approach is usually the first one undertaken by most companies. Rather than improving utilization quickly for free, or adjusting the planning with little effort, or spending some time and effort for decoupling, many companies go out and order an expensive new machine.
Not only is this slow and expensive, but also risky. In case you didn’t detect the correct bottleneck, you installed expensive additional capacity without any benefit for your system. Hence my strong advice: Before calling engineering, check if there are cheaper and faster options to ease your system capacity constraints.
Improve Changeovers
Even if you want to increase the capacity of the process, there are different approaches that also may work. For example, you can reduce changeover time. Through a SMED workshop, you may be able to change product types quicker. Please note that you probably should not change over less frequently, but rather more frequently due to the lot size issues shown in the last post on the impact of planning on the overall production capacity.
Improve Maintenance
Maintenance can also be investigated. There is also a trade-off between the time needed for too much maintenance and the risk of a machine failure. In Total Preventive Maintenance (TPM), it often feels like more maintenance is always better. I disagree. It depends. For example, too much maintenance (besides costing time and money) also has a possibility to put a machine out of whack, and you may produce more scrap until all settings have been optimized again after maintenance. In any case, if it is the bottleneck you can look at its maintenance too, in the search for improvement potential.
Reduce Scrap and Rework In and After the Bottleneck
And, if we are talking about scrap anyway: Any part that passes through the bottleneck but is scrapped afterward is lost capacity at the bottleneck machine. While it is always of interest to reduce scrap and rework, it is of particular importance at and after the bottleneck process. If a part gets thrown out after the bottleneck, you throw out not only the part, but also the urgently needed capacity at the bottleneck.
Don’t Put Your Worst Worker at the Bottleneck
Finally, don’t put your worst worker at the bottleneck process. Your employees have different skills, and some are probably better than others. The bottleneck process should be operated by a worker who can keep the machine running reasonably well, so that the use of the process does not suffer due to lack of experience of ability of the worker. However, please note that because a worker is not the best one, it does not automatically mean that he is a bad worker.
Is It Now Faster?
After detecting the bottleneck, selecting an improvement approach, and implementing the improvement, you expect your system speed to improve too. However, too often people are satisfied with the expectation of the improvement. This does not mean anything. Of course the system was changed, but is it now better than before? Don’t just believe or hope it is. Measure!
After an improvement in the (presumed) bottleneck process, check if your improvement actually did improve the system. (In fact, you should check after every and any improvement to determine if it really worked along the PDCA principles). The flowchart below shows an idealized approach after checking the new system speed and comparing it to the one before the changes.
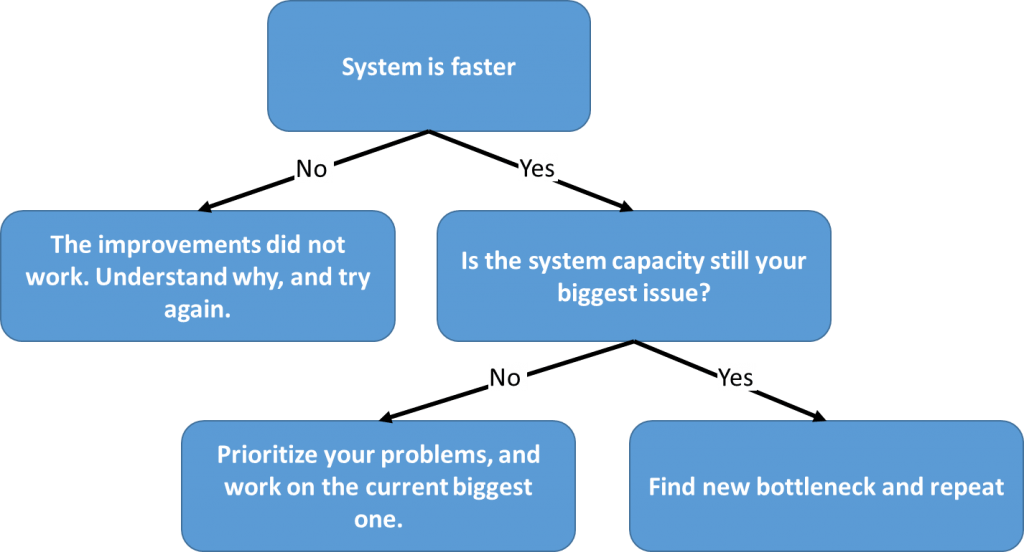
If your system did not improve, then something went wrong. Check what happened, why your changes did not improve the system, and what you would need to do to really improve the system speed. Then try again.
If your system is indeed faster, then congratulations. You’ve made a difference. Now see if the system not only increased, but if the reason why you did the bottleneck management in the first place is resolved. If your system capacity is still your most pressing issue, then even though you improved the system, it was not enough. Find the bottleneck again (due to your improvement, the bottleneck may have changed) and repeat the process.
If, however, your system is now fast enough that the system capacity is no longer your biggest issue, then you should pick the next urgent issue from your (probably) way-too-long list of problems.
Overall, among these different approaches to increase your system speed, there should be one that works for you. Please keep in mind that increasing utilization is the fastest and cheapest, and if possible you should start with that. Planning is usually next, but still pretty fast and often not expensive. Decoupling is also a possibility that can be explored. Adding machine capacity is usually the slowest and most expensive, and should be used only of the other approaches are unlikely to satisfy your needs.
This concludes this three-post series on bottlenecks. I hope this was interesting to you.
Now go out and organize your industry!
A great series of articles. Keep them coming Christoph. cheers, Rod.